Detecting
Emotional
Dynamic
Trajectories:
An Evaluation Framework
for Emotional Support in LLMs
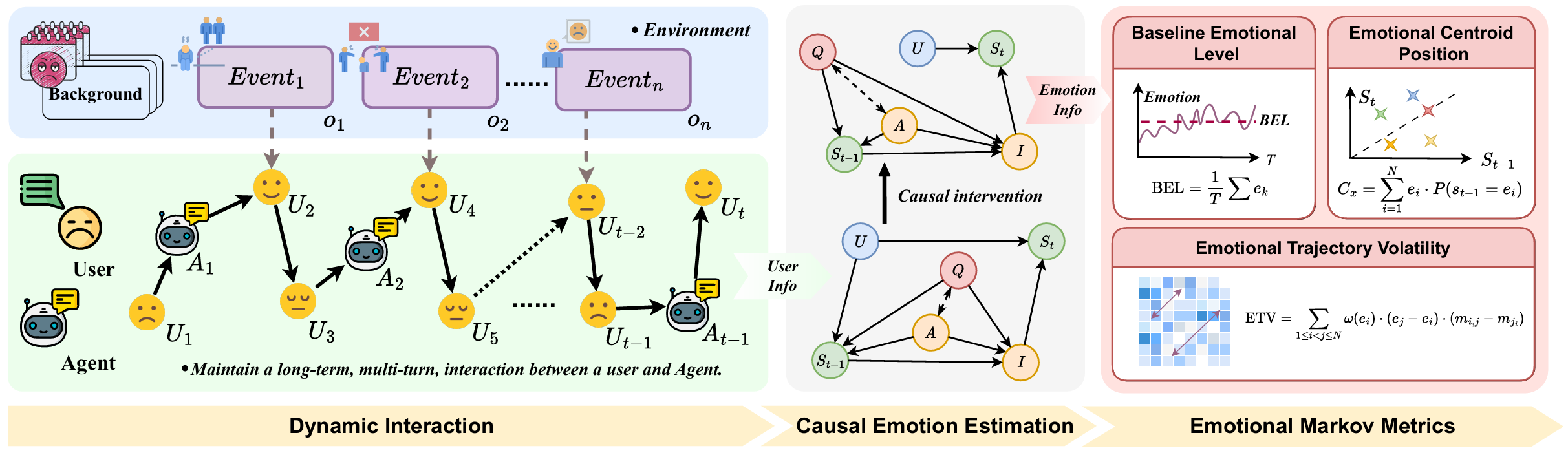
Overview of our evaluation framework for emotional support in long-term dialogues. It includes three modules: dynamic user-agent interaction under emotional events, causal emotion estimation based on Markov modeling, and three trajectory-level metrics including Baseline Emotional Level (BEL), Emotional Trajectory Volatility (ETV), and Emotional Centroid Position (ECP).
Abstract
Emotional support is a core capability in human-AI interaction, with applications including psychological counseling, role play, and companionship. However, existing evaluations of large language models (LLMs) often rely on short, static dialogues and fail to capture the dynamic and long-term nature of emotional support. To overcome this limitation, we shift from snapshot-based evaluation to trajectory-based assessment, adopting a user-centered perspective that evaluates models based on their ability to improve and stabilize user emotional states over time. Our framework constructs a large-scale benchmark consisting of 328 emotional contexts and 1,152 disturbance events, simulating realistic emotional shifts under evolving dialogue scenarios. To encourage psychologically grounded responses, we constrain model outputs using validated emotion regulation strategies such as situation selection and cognitive reappraisal. User emotional trajectories are modeled as a first-order Markov process, and we apply causally-adjusted emotion estimation to obtain unbiased emotional state tracking. Based on this framework, we introduce three trajectory-level metrics: Baseline Emotional Level (BEL), Emotional Trajectory Volatility (ETV), and Emotional Centroid Position (ECP). These metrics collectively capture user emotional dynamics over time and support comprehensive evaluation of long-term emotional support performance of LLMs. Extensive evaluations across a diverse set of LLMs reveal significant disparities in emotional support capabilities and provide actionable insights for model development.
Evaluation Environment and Interaction
A dynamic, theory-driven environment to robustly evaluate long-term emotional support.
Psychologically-Grounded Scenarios
Simulates 14 realistic distress situations drawn from established psychological and conflict theories.
Principled Support Strategies
Model behavior is guided and evaluated against six core emotion regulation strategies.
Dynamic Perturbations
Introduces 'emotional aggravation events' to stress-test the model's consistency and robustness.
Structured Trajectory Analysis
Formalizes dialogue as a state-based process for objective, trajectory-level metrics.
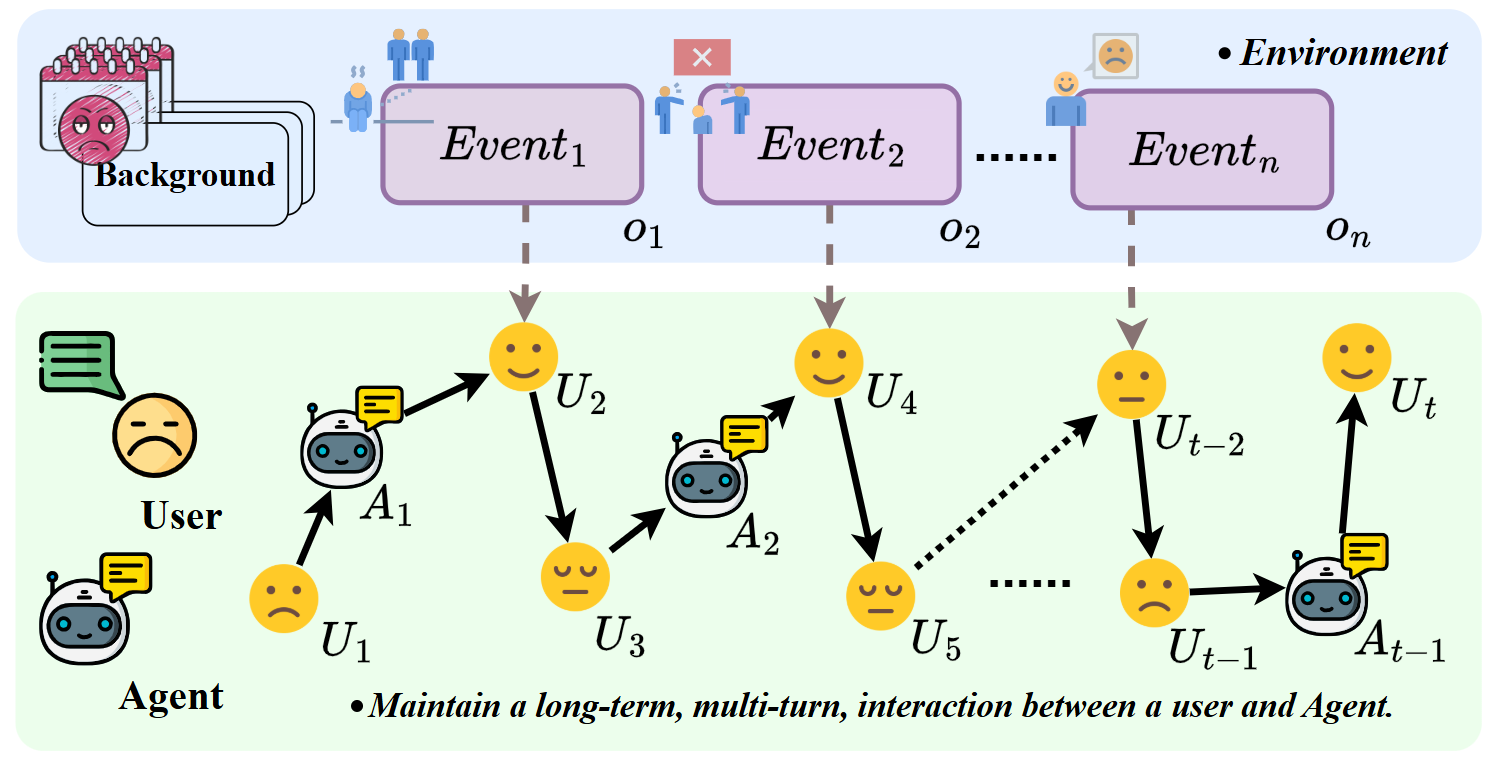
Overview of the dynamic user-agent interaction framework, including scenarios, strategies, and perturbations.
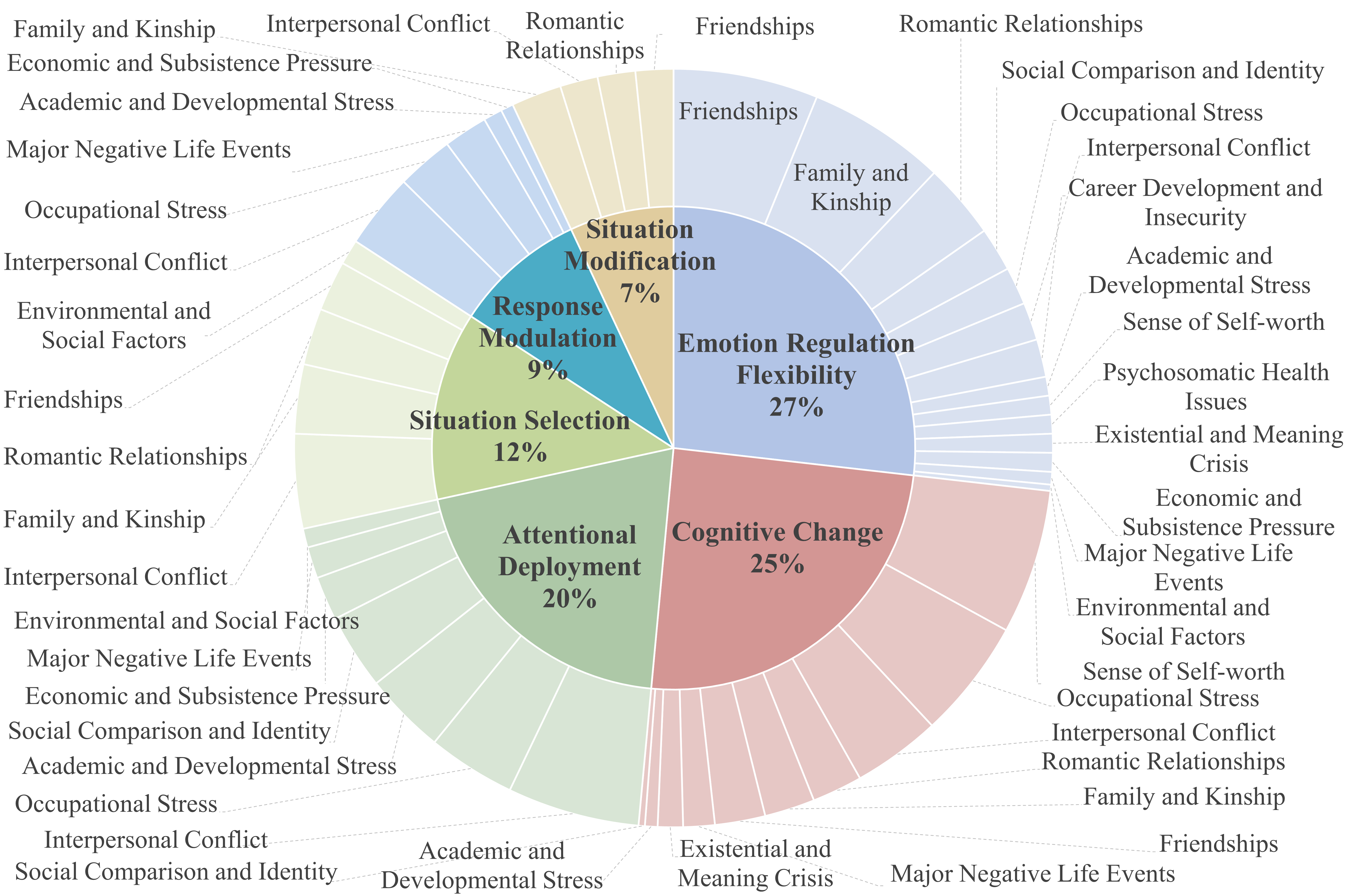
Distribution of emotion regulation strategies guiding model responses, constrained by psychological theory.
Dynamic Trajectories Metrics
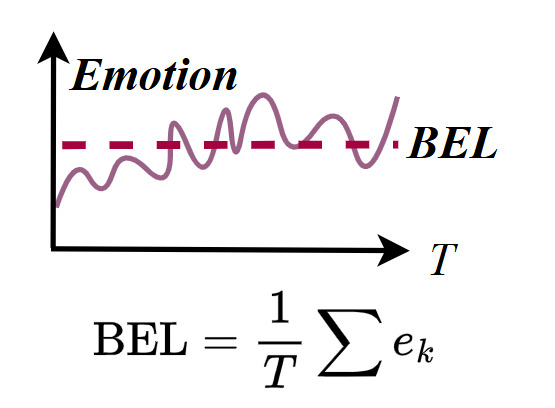
Baseline Emotional Level (BEL)
This metric quantifies the user's average emotional state throughout the entire dialogue. It provides a high-level overview of the interaction's overall positivity.
A higher BEL score indicates that the model is more effective at maintaining a positive emotional climate for the user over the long term.
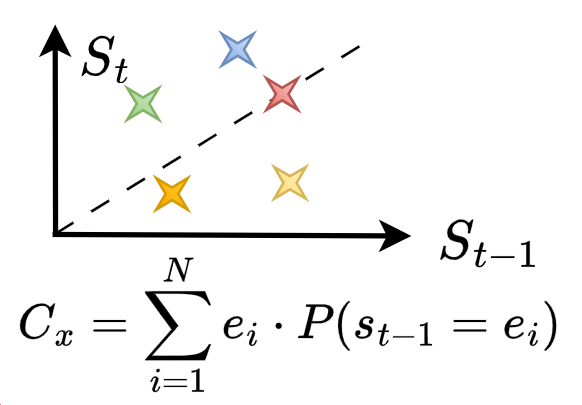
Emotional Centroid Position (ECP)
ECP visualizes the average emotional shift as a single centroid point (Cx, Cy). Cx represents the mean emotion before a model response, and Cy is the mean emotion after.
A centroid located above the y=x diagonal line indicates a net positive impact, showing the model systematically improves the user's emotional state.
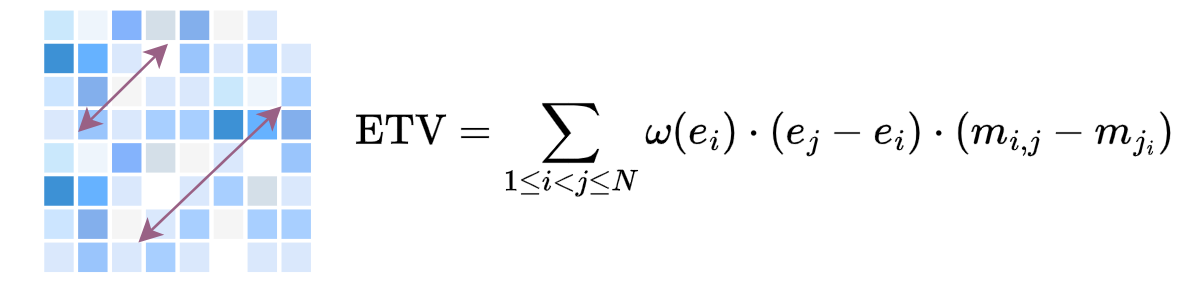
Emotional Trajectory Volatility (ETV)
ETV measures the model's ability to drive positive emotional shifts. It rewards upward transitions (e.g., from sad to neutral) more than downward ones, capturing the efficiency of emotional regulation.
A higher ETV signifies a stronger capability to elevate users from negative states and prevent regressions from positive ones.
Causally-Adjusted Emotion Estimation
Conventional emotion trackers often mistake correlation for causation. They can be misled by unobserved confounders, like a user's personality or mood that create spurious links between emotional states. This introduces bias, making it hard to measure a model's true impact. To solve this, we shift from statistical correlation to causal inference.
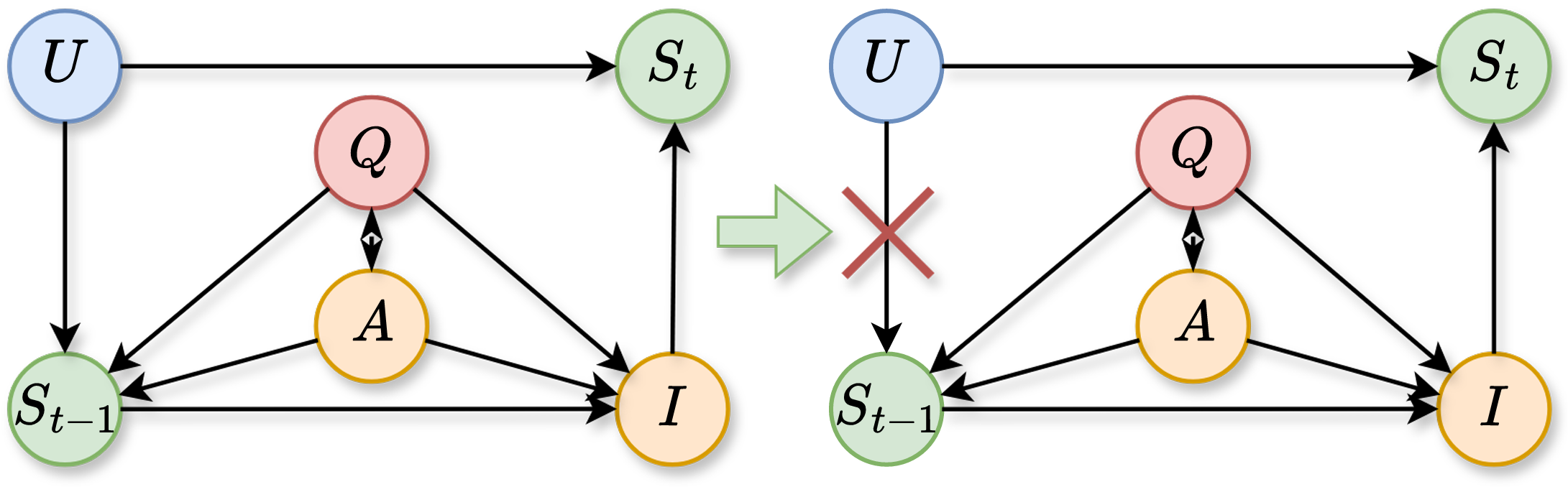
Causal graph illustrating emotional evolution with unobserved confounder. Right: theoretical intervention
do(Et-1) removes spurious correlation via backdoor adjustment.
Variable Definitions:
Q (User Dialogue History),
A (Model Dialogue History),
S (Emotion State),
I (Internal Thought),
U (Unobserved Confounder).
Using do-calculus, we mathematically intervene to remove these biasing effects. The result is a de-biased, post-intervention emotional distribution, which we use as our calibrated estimate:
P(St|do(St-1)) = ES't-1,Q',A' EQ,A[P(St|I,S't-1,Q',A')]By building our emotional trajectories from these causally-adjusted estimates, we ensure that our metrics (BEL, ETV, ECP) more faithfully reflect the model's true capability to provide emotional support.
Baseline Emotional Level (BEL) Results
The Baseline Emotional Level (BEL) metric assesses a model's ability to maintain a positive and stable emotional climate for the user over long conversations. Higher scores indicate a stronger performance in providing sustained emotional support. Below is a detailed comparison across various closed and open-sourced LLMs in both English and Chinese contexts.
| LLMs | Overall | CogChg | SitMod | AttDep | ERFlex | SitSel | ResMod | |||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| EN | ZH | EN | ZH | EN | ZH | EN | ZH | EN | ZH | EN | ZH | EN | ZH | |
| Closed-sourced LLMs | ||||||||||||||
| O3-2025-04-16 | 43.98 | 39.22 | 48.64 | 40.31 | 38.54 | 36.09 | 50.81 | 44.94 | 37.87 | 34.35 | 43.27 | 39.67 | 45.31 | 41.29 |
| Gemini-2.5-Pro | 42.65 | 37.41 | 44.18 | 33.91 | 43.65 | 37.51 | 37.12 | 39.48 | 38.47 | 30.46 | 42.18 | 40.65 | 49.00 | 44.80 |
| Claude-Opus-4 | 41.43 | 34.68 | 46.22 | 34.16 | 40.12 | 29.09 | 41.99 | 35.26 | 31.14 | 31.97 | 46.27 | 37.22 | 41.47 | 43.15 |
| Doubao-Seed-1.6 | 47.22 | 42.36 | 47.72 | 37.87 | 46.13 | 40.98 | 46.49 | 43.71 | 42.96 | 38.65 | 50.27 | 47.88 | 50.17 | 48.34 |
| Doubao-1.5-Pro-Character | 34.90 | 37.51 | 33.68 | 35.78 | 31.42 | 34.11 | 37.62 | 42.73 | 36.54 | 35.90 | 37.56 | 41.34 | 34.68 | 37.94 |
| ChatGPT-4o-Latest | 48.86 | 43.84 | 52.45 | 41.02 | 44.51 | 41.78 | 53.41 | 48.48 | 44.58 | 39.27 | 51.21 | 48.61 | 47.44 | 46.73 |
| GLM-4-Plus | 42.92 | 36.39 | 44.44 | 36.94 | 39.32 | 32.61 | 45.66 | 39.34 | 39.81 | 34.99 | 44.13 | 36.53 | 45.20 | 39.49 |
| ChatGLM-4 | 40.14 | 33.83 | 40.29 | 31.87 | 37.33 | 32.15 | 43.15 | 36.93 | 37.75 | 31.90 | 41.22 | 34.26 | 42.52 | 37.92 |
| Grok-4 | 39.73 | 31.55 | 42.41 | 28.60 | 37.19 | 29.31 | 43.73 | 36.15 | 35.68 | 26.82 | 37.56 | 35.63 | 41.92 | 35.82 |
| Open-sourced LLMs | ||||||||||||||
| Phi-4-14B | 44.69 | 37.42 | 44.10 | 33.58 | 42.41 | 32.56 | 47.48 | 42.13 | 42.15 | 37.08 | 45.71 | 42.62 | 47.87 | 40.84 |
| DeepSeek-V3 | 44.69 | 35.43 | 45.30 | 34.88 | 40.27 | 28.71 | 46.54 | 42.53 | 45.12 | 33.25 | 46.32 | 40.61 | 46.19 | 36.17 |
| DeepSeek-R1 | 47.57 | 45.32 | 48.87 | 43.43 | 43.57 | 40.77 | 46.22 | 50.64 | 46.55 | 47.01 | 52.90 | 47.88 | 48.23 | 45.31 |
| Qwen3-235B-A22B | 47.18 | 40.40 | 47.78 | 38.08 | 46.52 | 36.57 | 49.50 | 42.33 | 45.35 | 37.12 | 48.20 | 42.72 | 45.94 | 48.67 |
| Mistral-3.2-24B-Instruct | 33.93 | 27.93 | 32.71 | 27.63 | 30.26 | 24.09 | 36.13 | 29.46 | 31.06 | 26.25 | 36.98 | 30.15 | 38.90 | 31.93 |
| Kimi-K2-Preview | 49.00 | 45.11 | 49.96 | 47.57 | 49.34 | 41.74 | 48.55 | 50.00 | 43.86 | 41.04 | 49.81 | 45.73 | 52.11 | 45.19 |
| Qwen3-8B | 46.56 | 38.85 | 47.97 | 37.02 | 45.67 | 33.74 | 45.79 | 46.75 | 44.65 | 33.41 | 47.52 | 42.03 | 47.46 | 43.98 |
| Qwen3-32B | 46.87 | 40.88 | 47.32 | 38.03 | 44.17 | 35.98 | 47.81 | 46.34 | 46.69 | 36.36 | 47.37 | 42.73 | 48.79 | 49.99 |
| Llama-3.1-70B-Instruct | 42.94 | 31.07 | 42.15 | 30.23 | 41.12 | 30.13 | 46.55 | 30.47 | 43.69 | 30.38 | 44.51 | 33.40 | 40.98 | 32.66 |
Comparison of Baseline Emotional Level (BEL) across different models. For each case, the model with the highest BEL is marked in green, and the second-highest is underlined, indicating their relative effectiveness.
Emotional Trajectory Volatility (ETV) Results
Emotional Trajectory Volatility (ETV) measures each model's ability to promote a rapid and stable transition toward positive emotional states. Higher values suggest stronger emotional support effectiveness, rewarding upward emotional shifts more than downward ones.
| LLMs | Overall | CogChg | SitMod | AttDep | ERFlex | SitSel | ResMod | |||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| EN | ZH | EN | ZH | EN | ZH | EN | ZH | EN | ZH | EN | ZH | EN | ZH | |
| Closed-sourced LLMs | ||||||||||||||
| O3-2025-04-16 | 20.17 | 14.89 | 19.91 | 14.74 | 18.23 | 12.45 | 28.09 | 20.39 | 15.26 | 11.54 | 18.55 | 13.87 | 22.65 | 17.95 |
| Gemini-2.5-Pro | 18.95 | 13.39 | 18.65 | 9.47 | 19.80 | 14.43 | 21.01 | 19.05 | 15.57 | 10.45 | 17.99 | 13.26 | 20.84 | 15.85 |
| Claude-Opus-4 | 19.89 | 10.81 | 20.15 | 9.64 | 20.13 | 7.47 | 26.10 | 14.53 | 13.12 | 7.56 | 21.03 | 13.26 | 19.38 | 14.83 |
| Doubao-Seed-1.6 | 21.55 | 15.31 | 19.92 | 11.68 | 21.97 | 13.81 | 25.38 | 19.25 | 18.46 | 14.74 | 21.72 | 15.69 | 22.94 | 19.48 |
| Doubao-1.5-Pro-Character | 17.72 | 14.48 | 15.62 | 11.66 | 16.13 | 12.53 | 23.45 | 21.40 | 16.46 | 15.02 | 17.71 | 12.08 | 19.11 | 16.88 |
| ChatGPT-4o-Latest | 21.99 | 15.40 | 22.09 | 13.26 | 20.75 | 13.32 | 29.02 | 20.74 | 19.23 | 13.55 | 20.62 | 15.37 | 21.30 | 18.56 |
| GLM-4-Plus | 21.00 | 12.56 | 20.55 | 12.63 | 18.22 | 9.88 | 25.29 | 17.72 | 20.03 | 11.63 | 19.92 | 9.77 | 23.68 | 15.13 |
| ChatGLM-4 | 20.25 | 11.56 | 19.58 | 8.90 | 19.15 | 10.29 | 25.05 | 15.14 | 17.53 | 11.57 | 19.25 | 9.32 | 22.17 | 16.25 |
| Grok-4 | 18.85 | 8.73 | 17.83 | 6.71 | 19.19 | 7.30 | 25.40 | 11.45 | 15.53 | 5.61 | 15.61 | 9.79 | 20.51 | 13.51 |
| Open-sourced LLMs | ||||||||||||||
| Phi-4-14B | 21.37 | 13.21 | 21.27 | 9.94 | 19.66 | 11.24 | 25.65 | 19.12 | 18.99 | 13.89 | 20.12 | 13.60 | 23.64 | 14.33 |
| DeepSeek-V3 | 20.32 | 12.02 | 19.52 | 10.77 | 18.82 | 7.57 | 25.04 | 17.32 | 20.39 | 10.77 | 18.98 | 14.22 | 20.49 | 14.32 |
| DeepSeek-R1 | 20.38 | 15.30 | 18.27 | 13.20 | 20.68 | 14.26 | 23.76 | 21.70 | 19.77 | 15.37 | 20.03 | 13.25 | 20.97 | 15.92 |
| Qwen3-235B-A22B | 21.13 | 14.02 | 19.40 | 11.89 | 23.10 | 13.66 | 26.46 | 19.38 | 19.99 | 11.88 | 19.86 | 11.67 | 18.47 | 17.35 |
| Mistral-3.2-24B-Instruct | 15.93 | 7.01 | 13.41 | 6.64 | 14.88 | 4.19 | 23.75 | 9.58 | 13.19 | 6.43 | 16.09 | 7.54 | 16.63 | 9.19 |
| Kimi-K2-Preview | 22.92 | 16.74 | 21.59 | 14.36 | 25.15 | 16.20 | 26.12 | 21.86 | 20.37 | 16.81 | 19.56 | 16.01 | 24.84 | 17.00 |
| Qwen3-8B | 21.22 | 12.73 | 19.56 | 9.69 | 21.87 | 11.34 | 24.61 | 20.59 | 20.50 | 10.91 | 20.62 | 11.41 | 20.99 | 15.22 |
| Qwen3-32B | 21.81 | 14.91 | 19.99 | 11.97 | 21.98 | 14.20 | 28.14 | 21.77 | 19.96 | 11.42 | 19.25 | 12.99 | 22.95 | 19.61 |
| Llama-3.1-70B-Instruct | 19.09 | 9.75 | 16.16 | 8.52 | 19.03 | 10.94 | 24.13 | 11.44 | 18.99 | 8.89 | 19.71 | 9.40 | 18.39 | 9.64 |
ETV results comparison. The model with the highest ETV is marked in green, and the second-highest is underlined.
Centroid Position & Trajectory Visualization
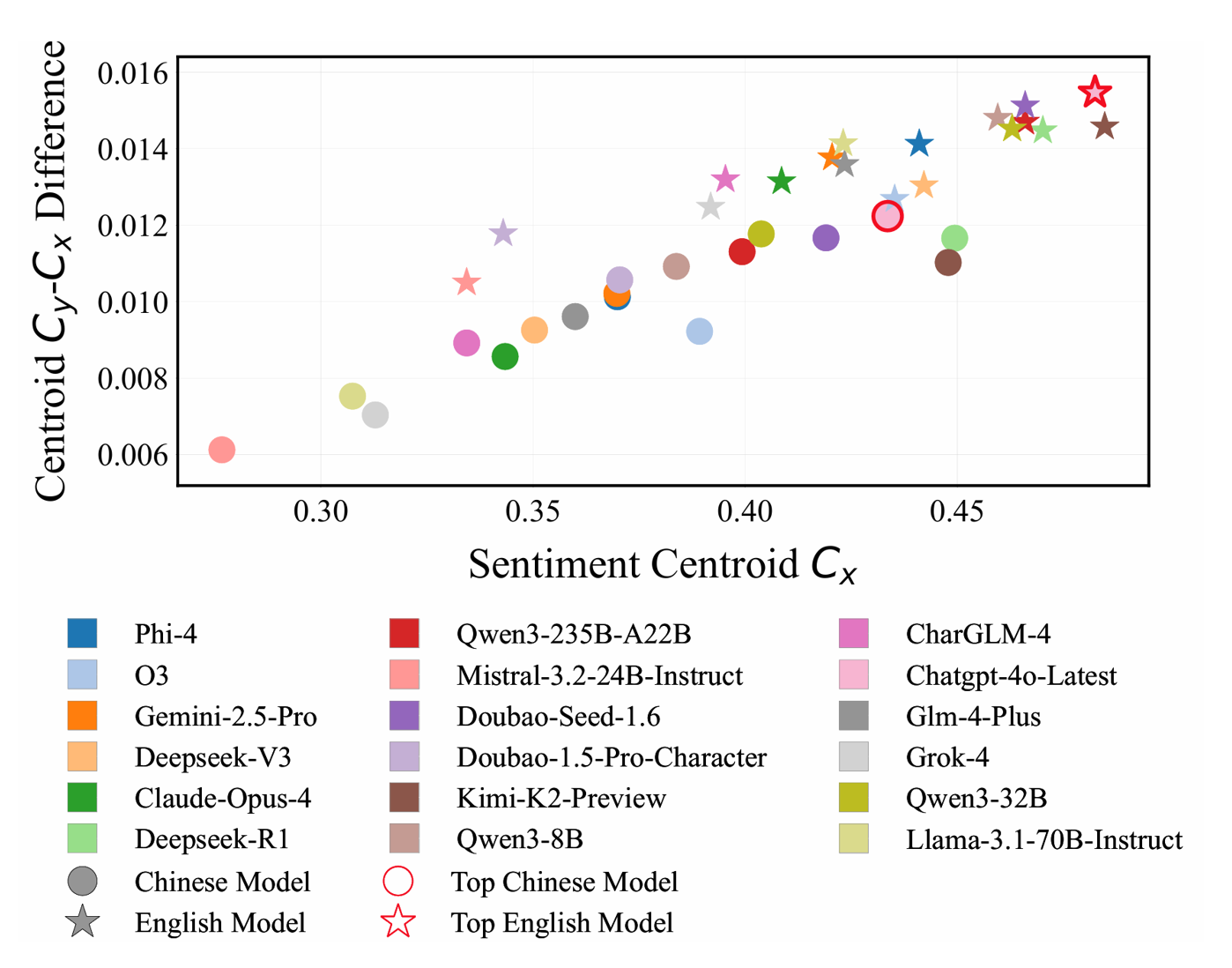
Emotional Centroid Position
We visualize the emotional guidance capabilities of LLMs using an Emotional Centroid Position. The horizontal axis (Cx) reflects the overall positivity of a dialogue, while the vertical axis (Cy - Cx) measures the model's ability to consistently improve the user's emotion.
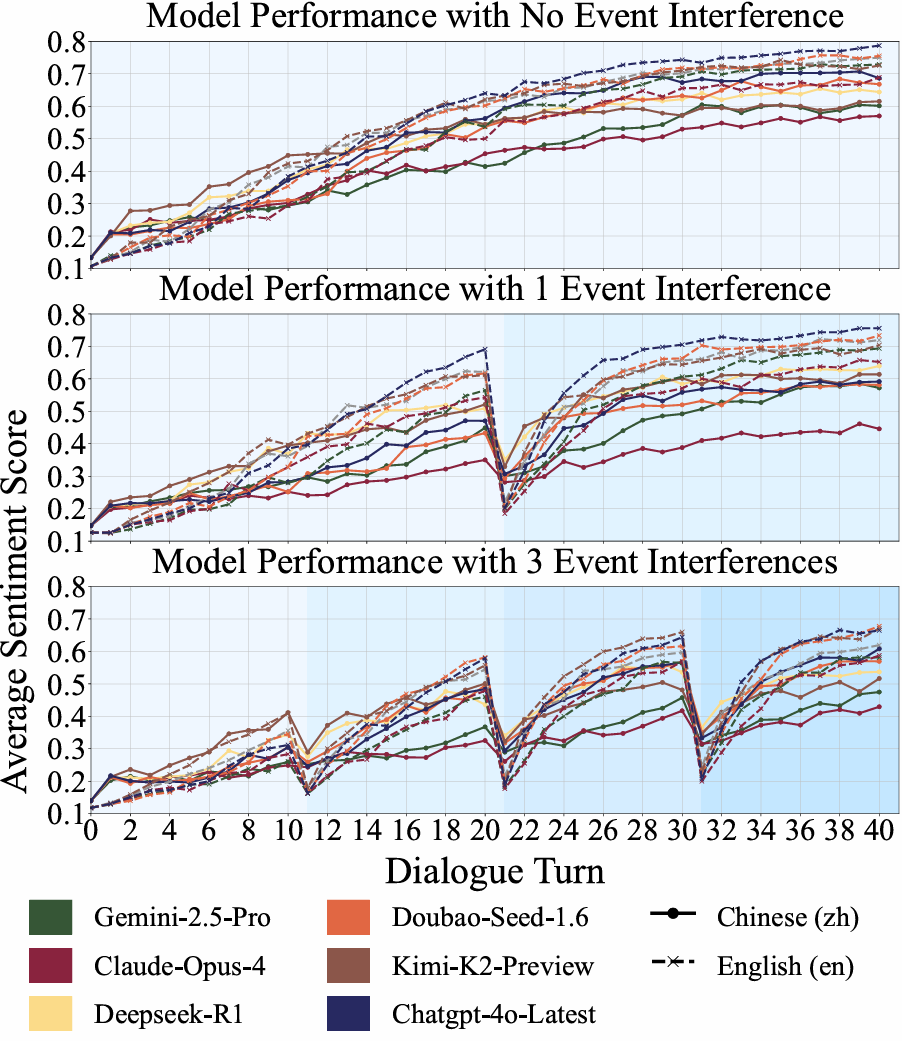
Trajectory Under Disturbance
We visualize emotional trajectories under different levels of disturbance. The analysis shows:
- Models with higher ETV scores help users recover from low states faster.
- Without disturbances, most models quickly return users to a neutral state.
- Stronger models show more resilience when multiple disturbances occur.
BibTeX
@article{tan2025detectingemotionaldynamictrajectories,
title={Detecting Emotional Dynamic Trajectories: An Evaluation Framework for Emotional Support in Language Models},
author={Zhouxing Tan and Ruochong Xiong and Yulong Wan and Jinlong Ma and Hanlin Xue and Qichun Deng and Haifeng Jing and Zhengtong Zhang and Depei Liu and Shiyuan Luo and Junfei Liu},
year={2025},
eprint={2511.09003},
archivePrefix={arXiv},
primaryClass={cs.CL},
journal={ArXiv},
url={https://arxiv.org/abs/2511.09003},
}